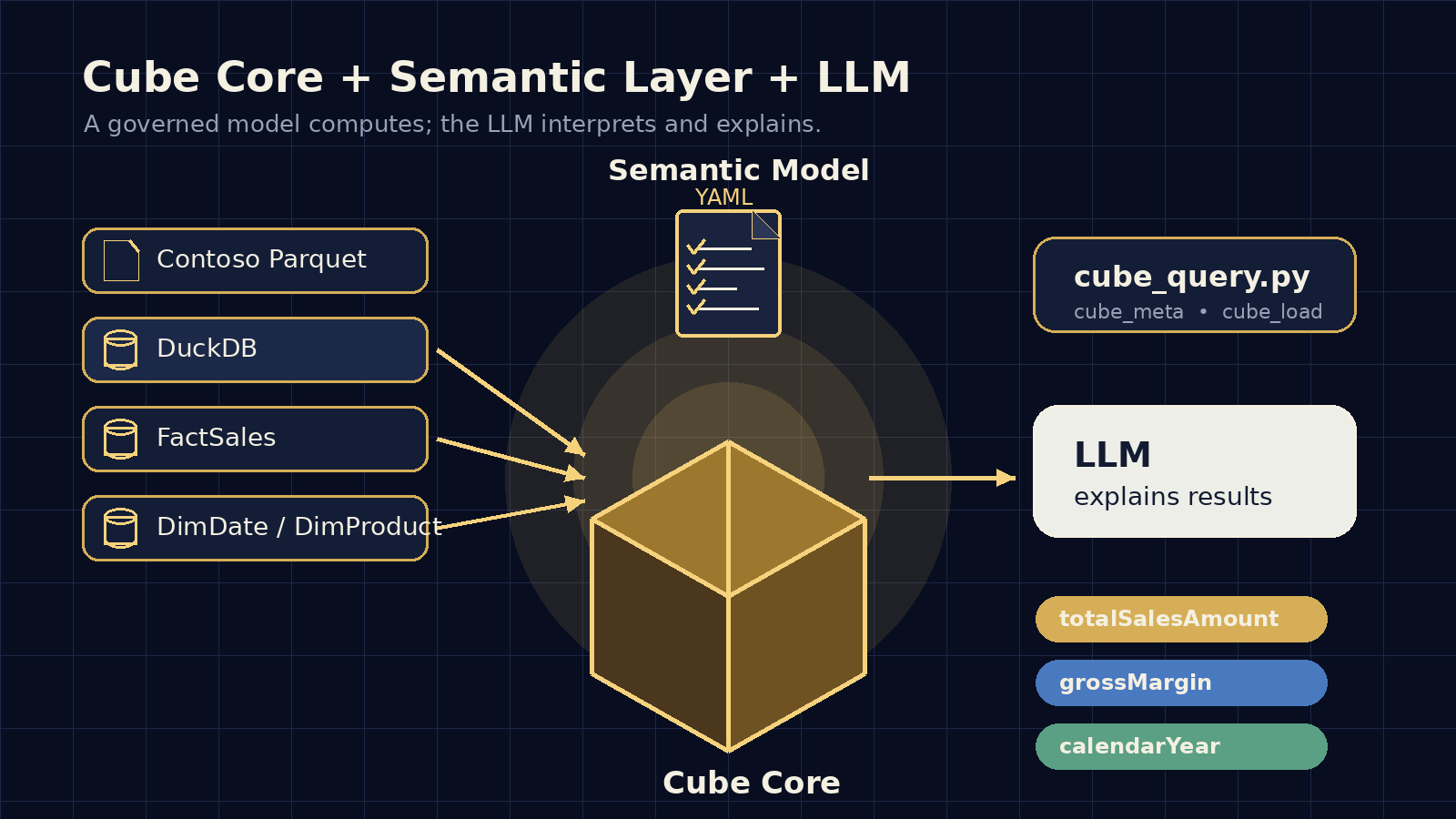
Modal for Data Science: Free GPU Compute for Your Python Projects
Learn how to use Modal — a serverless GPU platform with $30/month free credits — to run data science and machine learning workloads from your local Jupyter notebooks and Python scripts. Covers setup with uv, notebook integration, GPU selection, and common pitfalls.
Data Science